Globally and Locally Consistent Image Completion

|

|

|

|

|

|

|

|
|
|
|
|
|
|
|
|
|
|
We present a novel approach for image completion that results in images that are both locally and globally consistent. With a fully-convolutional neural network, we can complete images of arbitrary resolutions by filling-in missing regions of any shape. To train this image completion network to be consistent, we use global and local context discriminators that are trained to distinguish real images from completed ones. The global discriminator looks at the entire image to assess if it is coherent as a whole, while the local discriminator looks only at a small area centered at the completed region to ensure the local consistency of the generated patches. The image completion network is then trained to fool the both context discriminator networks, which requires it to generate images that are indistinguishable from real ones with regard to overall consistency as well as in details. We show that our approach can be used to complete a wide variety of scenes. Furthermore, in contrast with the patch-based approaches such as PatchMatch, our approach can generate fragments that do not appear elsewhere in the image, which allows us to naturally complete the images of objects with familiar and highly specific structures, such as faces.
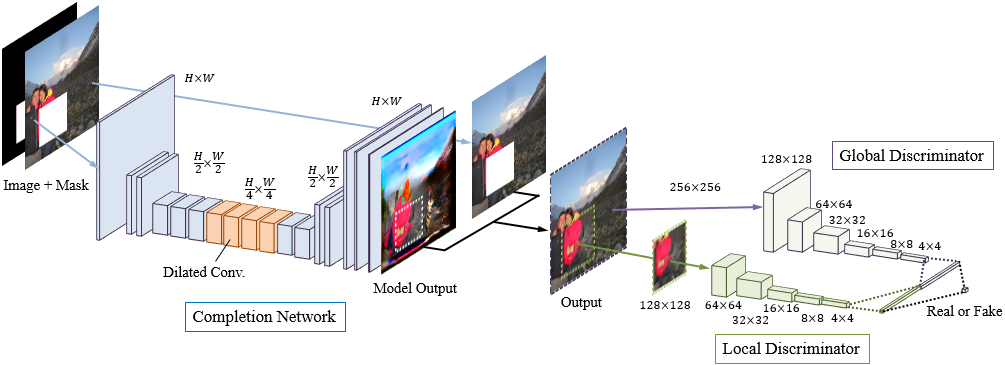
Our architecture is composed of three networks: a completion network, a
global context discriminator, and a local context discriminator. The
completion network is fully convolutional and used to complete
the image, while both the global and the local context discriminators
are auxiliary networks used exclusively for training. These
discriminators are used to determine whether or not an image has
been completed consistently. The global discriminator takes the
full image as input to recognize global consistency of the scene,
while the local discriminator looks only at a small region around
the completed area in order to judge the quality of more detailed
appearance.
 Original |
 Input |
 Output |

 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Comparison with Photoshop CS6 Content Aware Fill (PatchMatch [Barnes et al. 2009]), [Darabi et al. 2012], [Huang et al. 2014], and [Pathak et al. 2016] on a diverse set of scenes using random masks.
@Article{IizukaSIGGRAPH2017,
author =
{Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Ishikawa},
title = {{Globally and Locally Consistent Image Completion}},
journal = "ACM Transactions on Graphics
(Proc. of SIGGRAPH 2017)",
year = 2017,
volume = 36,
number = 4,
pages = 107:1--107:14,
articleno = 107,
} This work was partially supported by JST ACT-I Grant Number JPMJPR16U3 and JST CREST Grant Number JPMJCR14D1.























