DeepRemaster: Temporal Source-Reference Attention Networks for Comprehensive Video Enhancement

The remastering of vintage film comprises of a diversity of sub-tasks including super-resolution, noise removal, and contrast enhancement which jointly aim to restore the deteriorated film medium to its original state. Additionally, due to the technical limitations of the time, most vintage film is either recorded in black and white, or has low quality colors, for which colorization becomes necessary. In this work, we propose a single framework to tackle the entire remastering task semi-interactively. Our work is based on temporal convolutional neural networks with attention mechanisms trained on videos with data-driven deterioration simulation. Our proposed source-reference attention allows the model to handle an arbitrary number of reference color images to colorize long videos without the need for segmentation while maintaining temporal consistency. Quantitative analysis shows that our framework outperforms existing approaches, and that, in contrast to existing approaches, the performance of our framework increases with longer videos and more reference color images.
The model is input a sequence of black and white images which are restored using a pre-processing network and used as the luminance channel of the final output video. Afterwards, a source-reference network uses an arbitrary number of reference color images in conjunction with the output of the pre-processing network to produce the final chrominance channels of the video. Source-reference attention is used to allow the model to employ the color of similar regions in the reference color images when colorizing the video. The output of the model is a remastered video of the input.
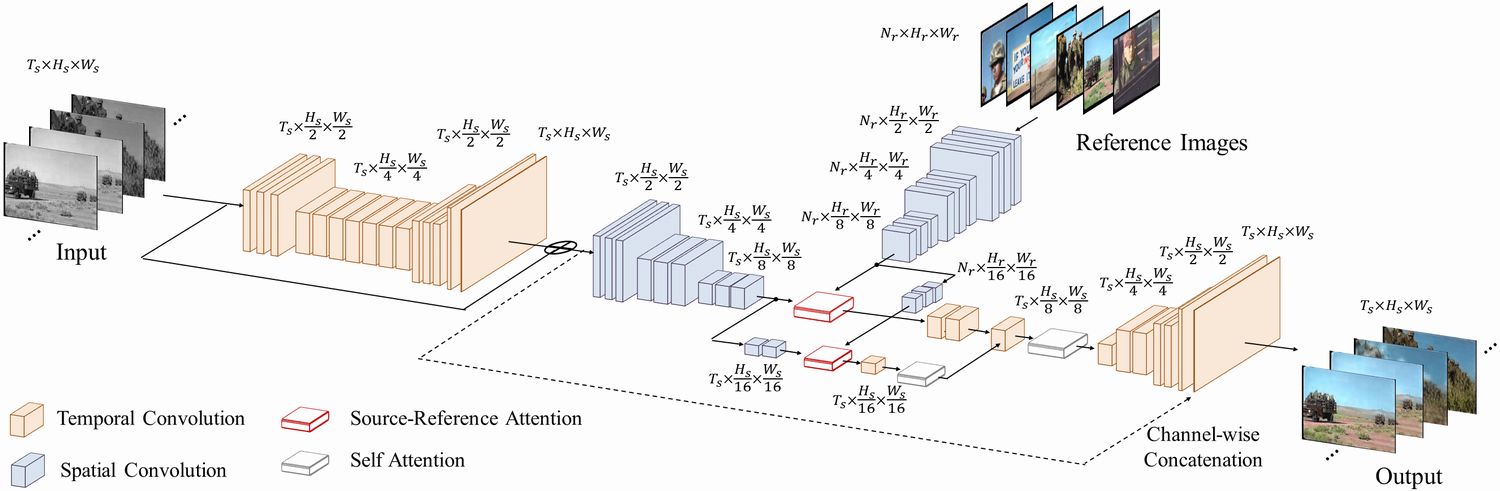
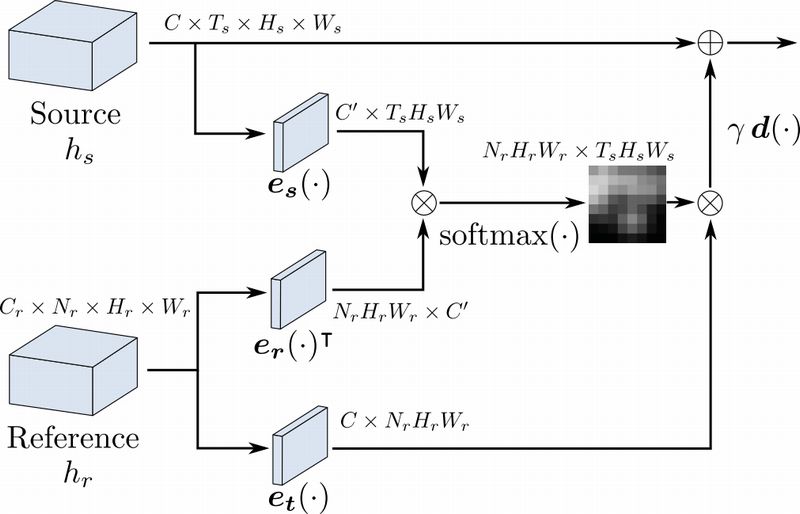
Fig. (a) shows an overview of the temporal source-reference attention layer. This layer takes both a set of reference feature maps and a set of source feature maps as an input, and outputs a new set of feature maps of the same dimension as the source feature maps. This attention allows using non-local features from the reference features to perform a transformation of the source reference features. This transformation is done while conserving the local information similar to a purely convolutional layer. The input and output dimensions of the different components are shown for reference.
Fig. (b) and (c) show a comparison between recursion-based and attention-based Convolutional Neural Networks (CNN) when processing an input video x with reference images z . Recursion-based networks simply propagate the information frame-by-frame, and because of this can not be processed in parallel and are unable to form long-term dependencies. Each time a new reference image is used, the propagation is restarted, and temporal coherency is lost. Source-reference attention-based networks, such as our approach, are able to use all the reference information when processing any the frames.
 (a) Temporal source-reference attention |
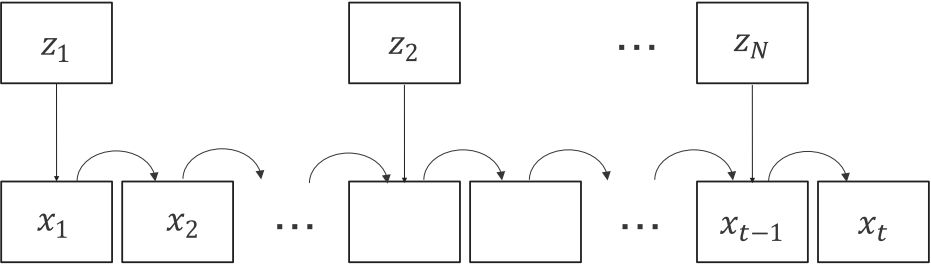 (b) Recursion-based approach |
|---|---|
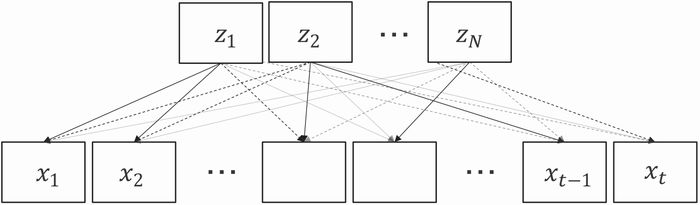 (c) Our attention-based approach |
We performed remastering on diverse challenging real world vintage films. The upper images in each video are reference images used for colorization. The opacity of each reference image indicates importance for the frames. Note that the importance is computed as a mean value of the attention of the reference image.
Comparison with combinations of existing restoration and colorization approaches, i.e., the approach of [Zhang et al. 2017b] and [Yu et al. 2018] for restoration, and [Zhang et al. 2017a] and [Vondrick et al. 2018] for colorization on real world vintage films and the videos from Youtube-8M dataset. We use the same reference images in the above remastering results for the vintage films. For the videos from Youtube-8M dataset, we randomly sample a subset of 300 frames for videos from Youtube-8M dataset, and apply both example-based and algorithm-based deterioration effects. For the reference color images, we provide every 60th frame starting from the first frame as a reference image. In the following results, each video is an input video, [Zhang et al. 2017b] and [Zhang et al. 2017a], [Yu et al. 2018] and [Zhang et al. 2017a], [Zhang et al. 2017b] and [Vondrick et al. 2018], [Yu et al. 2018] and [Vondrick et al. 2018], and ours, in order from left to right, top to bottom.
|
Input Video
[Zhang et al. 2017b] and [Zhang et al. 2017a]
[Yu et al. 2018] and [Zhang et al. 2017a]
|
|---|
|
[Zhang et al. 2017b] and [Vondrick et al. 2018]
[Yu et al. 2018] and [Vondrick et al. 2018]
Ours
|
Additional results are here.
@Article{IizukaSIGGRAPHASIA2019,
author =
{Satoshi Iizuka and Edgar Simo-Serra},
title = {{DeepRemaster: Temporal Source-Reference Attention Networks for Comprehensive Video Enhancement}},
journal = "ACM Transactions on Graphics
(Proc. of SIGGRAPH Asia 2019)",
year = 2019,
volume = 38,
number = 6,
pages = 1--13,
articleno = 176,
}
This work was partially supported by JST ACT-I (Iizuka, Grant Number: JPMJPR16U3), JST PRESTO (Simo-Serra, Grant Number: JPMJPR1756), and JST CREST (Iizuka and Simo-Serra, Grant Number: JPMJCR14D1).